")
")
Sicurezza del Machine Learning
Stato della ricerca sulla sicurezza del Machine Learning
Secure ML: ricerca Tutorial: Wild Patterns Secure ML Library
Secure ML: ricerca Tutorial: Wild Patterns Secure ML Library
Le tecnologie di apprendimento automatico (Machine Learning) e di intelligenza artificiale hanno conseguito risultati notevoli in ambiti relativi alla computer vision e alla cybersecurity. Dalle self-driving cars (auto senza conducente) ai sistemi di visione robotizzata, fino agli strumenti di rilevazione di spam e malware, tali tecnologie si sono diffuse ampiamente nella nostra quotidianità.
Tuttavia, quando vengono implementate in contesti reali, queste tecnologie possono incontrare condizioni ostili o variazioni impreviste dei dati di input. Comprendere le loro proprietà di sicurezza (e progettare adeguate contromisure) è quindi diventata una sfida - la nostra sfida - di ricerca necessaria per lo sviluppo di sistemi di AI sicuri.
Interviste al nostro staff sulla sicurezza delle AI e del Machine Learning:
8 Luglio 2019: BBC News, AI pilot 'sees' runway and lands automatically
24 Aprile 2019: New Scientist, Machine mind hack: The new threat that could scupper the AI revolution
3 Marzo 2019: El Pais, La guerra de los robots: la salvación antes de la era ‘fake’
2 Febbraio 2019: The Register, Fool ML once, shame on you. Fool ML twice, shame on... the AI dev?
3 Gennaio 2019: Bloomberg News, Artificial Intelligence Vs. the Hackers
29 Aprile 2018: WIRED, AI can help cybersecurity - if it can fight through the hype27 Luglio 2020: WIRED, Facebook’s ‘Red Team’ Hacks Its Own AI Programs
11 Maggio 2020: WIRED, This ugly t-shirt makes you invisible to facial recognition tech
10 Novembre 2019: The New York Times, Building a World Where Data Privacy Exists Online8 Luglio 2019: BBC News, AI pilot 'sees' runway and lands automatically
24 Aprile 2019: New Scientist, Machine mind hack: The new threat that could scupper the AI revolution
3 Marzo 2019: El Pais, La guerra de los robots: la salvación antes de la era ‘fake’
2 Febbraio 2019: The Register, Fool ML once, shame on you. Fool ML twice, shame on... the AI dev?
3 Gennaio 2019: Bloomberg News, Artificial Intelligence Vs. the Hackers
9 Marzo 2018: WIRED, AI has a hallucination problem that’s proving tough to fix
Leggi tutti gli articoli...
Leggi tutti gli articoli...
Il nostro team di ricerca è stato tra i primi a:
- dimostrare che gli algoritmi di apprendimento automatico sono vulnerabili di fronte a manipolazioni basate sui gradienti dei dati di input, sia durante la fase di test (attacchi di evasione - evasion attacks) sia durante l'addestramento (attacchi di avvelenamento - poisoning attacks);
- configurare un quadro sistematico per la valutazione della sicurezza degli algoritmi di apprendimento;
- sviluppare contromisure adeguate per migliorare la loro sicurezza.
Gli attacchi evasivi (evasion attacks, anche recentemente chiamati adversarial examples) consistono nel manipolare i dati di input per eludere un classificatore addestrato al momento del test. Questi possono includere, ad esempio, la manipolazione tramite codice malware col fine di ottenere un campione corrispondente erroneamente classificato come legittimo, o la manipolazione di immagini per ingannare il riconoscimento di un oggetto.
Il nostro staff di ricerca è stato tra i primi a dimostrare il funzionamento di questi attacchi contro noti algoritmi di apprendimento automatico, tra cui support vector machines e reti neurali (Biggio et al., 2013). Gli attacchi evasivi sono stati indipendentemente derivati nel campo del deep learning e, in seguito, della computer vision (C. Szegedy et al., 2014), sotto il nome di adversarial examples, ovvero immagini che possono essere classificate in modo errato da algoritmi di deep learning, pur essendo solo impercettibilmente distorte.
Il nostro staff di ricerca è stato tra i primi a dimostrare il funzionamento di questi attacchi contro noti algoritmi di apprendimento automatico, tra cui support vector machines e reti neurali (Biggio et al., 2013). Gli attacchi evasivi sono stati indipendentemente derivati nel campo del deep learning e, in seguito, della computer vision (C. Szegedy et al., 2014), sotto il nome di adversarial examples, ovvero immagini che possono essere classificate in modo errato da algoritmi di deep learning, pur essendo solo impercettibilmente distorte.
Gli attacchi contaminativi (o attacchi di avvelenamento, poisoning attacks) sono più subdoli. Il loro obiettivo è quello di ingannare gradualmente l'algoritmo di apprendimento durante la fase di addestramento, manipolando solo una piccola parte dei dati di addestramento, al fine di aumentare significativamente il numero di campioni errati al momento del test, causando un denial of service. Questi attacchi richiedono l'accesso ai dati utilizzati per addestrare l'algoritmo di classificazione (questo è possibile solo in alcuni contesti specifici).
Il nostro team di ricerca ha dimostrato il funzionamento di attacchi contaminativi contro support vector machines, le quali possono essere severamente compromesse da questo tipo di attacco (Biggio et al., 2012), poi contro LASSO, ridge and elastic-net regression (Xiao et al., 2015; Jagielski et al., 2018), e più recentemente contro reti neurali e algoritmi di deep learning (L. Muñoz-González et al., 2017).
Il nostro team di ricerca ha dimostrato il funzionamento di attacchi contaminativi contro support vector machines, le quali possono essere severamente compromesse da questo tipo di attacco (Biggio et al., 2012), poi contro LASSO, ridge and elastic-net regression (Xiao et al., 2015; Jagielski et al., 2018), e più recentemente contro reti neurali e algoritmi di deep learning (L. Muñoz-González et al., 2017).
Tutta la storia dell'Adversarial Machine Learning nell'articolo "Wild Patterns: Ten Years after the Rise of Adversarial Machine Learning".
Cronologia
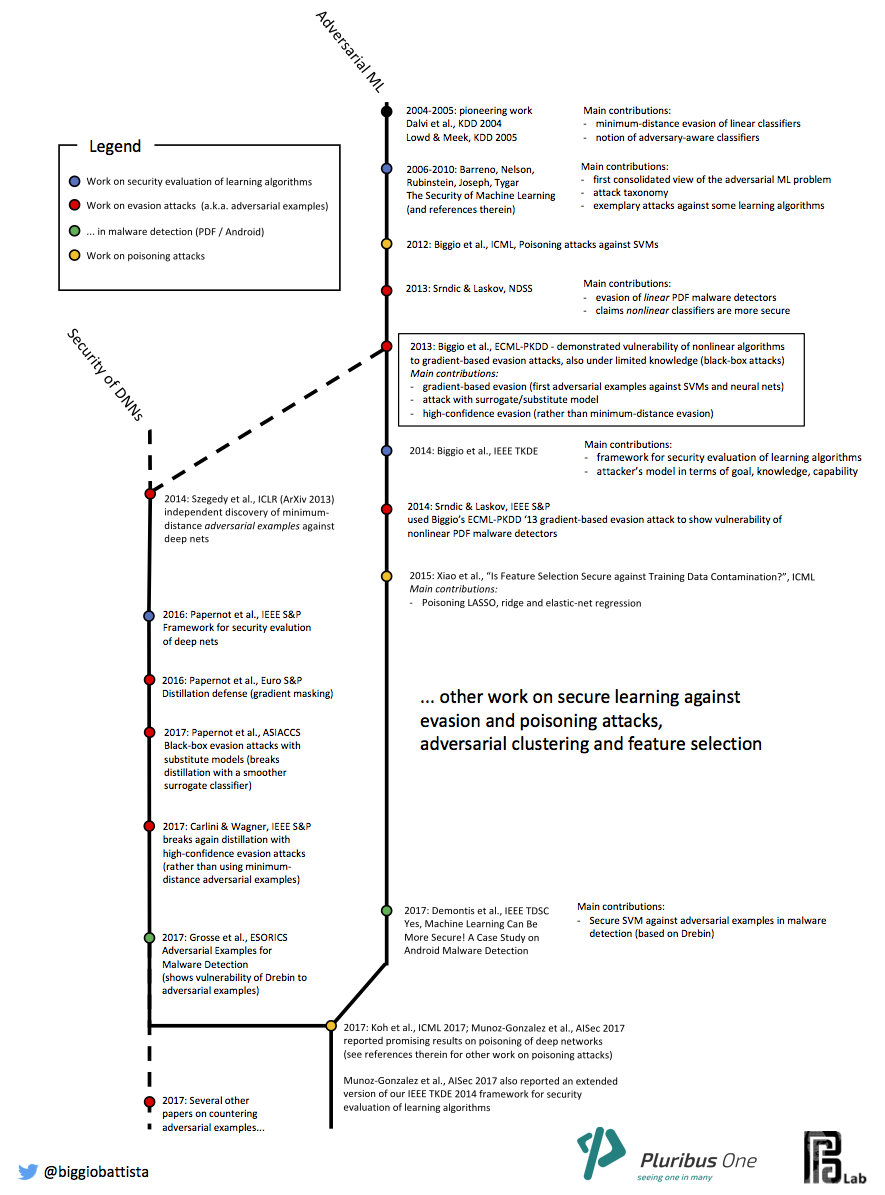
Pubblicazioni rilevanti
- Poisoning Attacks against Support Vector Machines, B. Biggio, B. Nelson, P. Laskov. In ICML 2012
- Evasion Attacks against Machine Learning at Test Time, B. Biggio, I. Corona, D. Maiorca, B. Nelson, N. Šrndić, P. Laskov, G. Giacinto, F. Roli. In ECML-PKDD 2013
- Security Evaluation of Pattern Classifiers under Attack, B. Biggio, G. Fumera, F. Roli. In IEEE TKDE 2014
- Is Feature Selection Secure against Training Data Poisoning?, H. Xiao, B. Biggio, G. Brown, G. Fumera, C. Eckert, F. Roli. In ICML
- Is Deep Learning Safe for Robot Vision? Adversarial Examples against the iCub Humanoid, M. Melis, A. Demontis, B. Biggio, G. Brown, G. Fumera, F. Roli. In 2017 ICCV Workshop ViPAR
- Towards Poisoning of Deep Learning Algorithms with Back-gradient Optimization, L. Muñoz-González, B. Biggio, A. Demontis, A. Paudice, V. Wongrassamee, E. C. Lupu, F. Roli. In AISec 2017
- Yes, Machine Learning Can Be More Secure! A Case Study on Android Malware Detection, A. Demontis, M. Melis, B. Biggio, D. Maiorca, D. Arp, K. Rieck, I. Corona, G. Giacinto, F. Roli. In IEEE TDSC 2017
- Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning, B. Biggio, F. Roli. In Pattern Recognition (under review)
Presentazioni rilevanti

La cosa triste, a proposito dell'intelligenza artificiale, è che le manca l'artificio e quindi l'intelligenza
Jean Baudrillard, Sociologo


